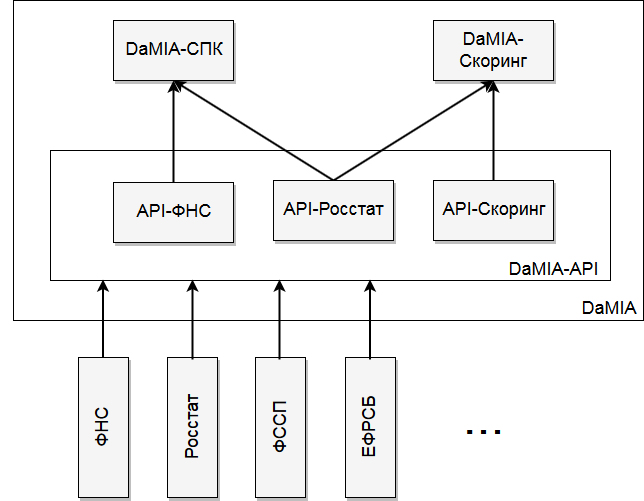
3. Система DaMIA-Скоринг
3.1 Исходные данные для скоринга
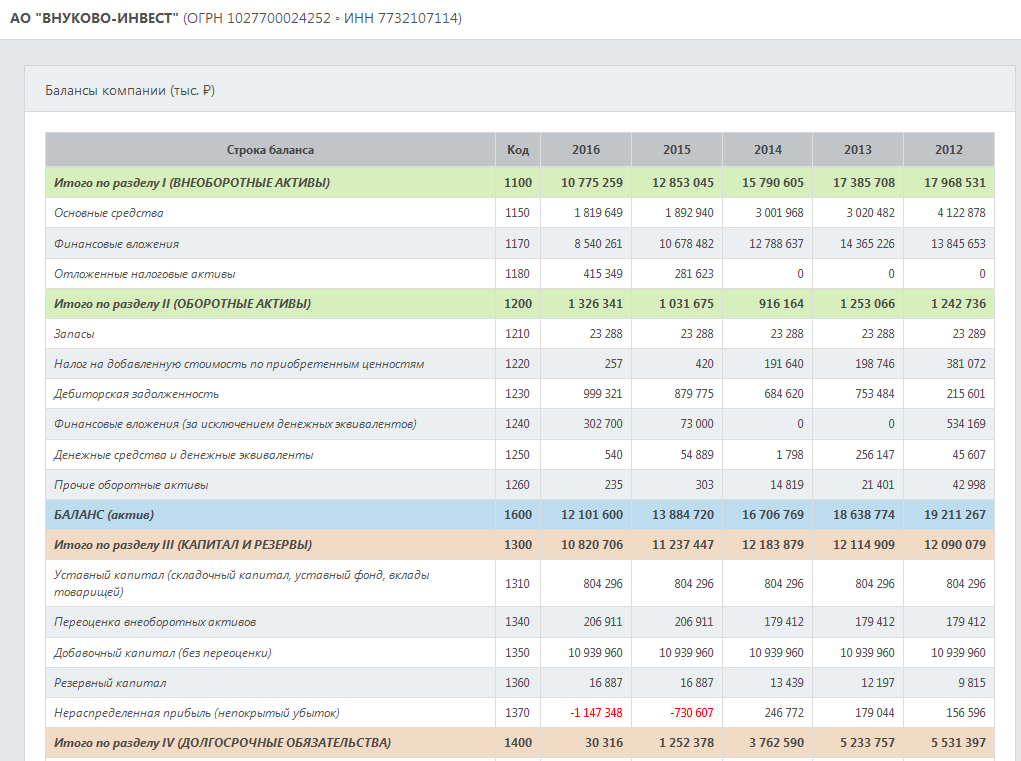
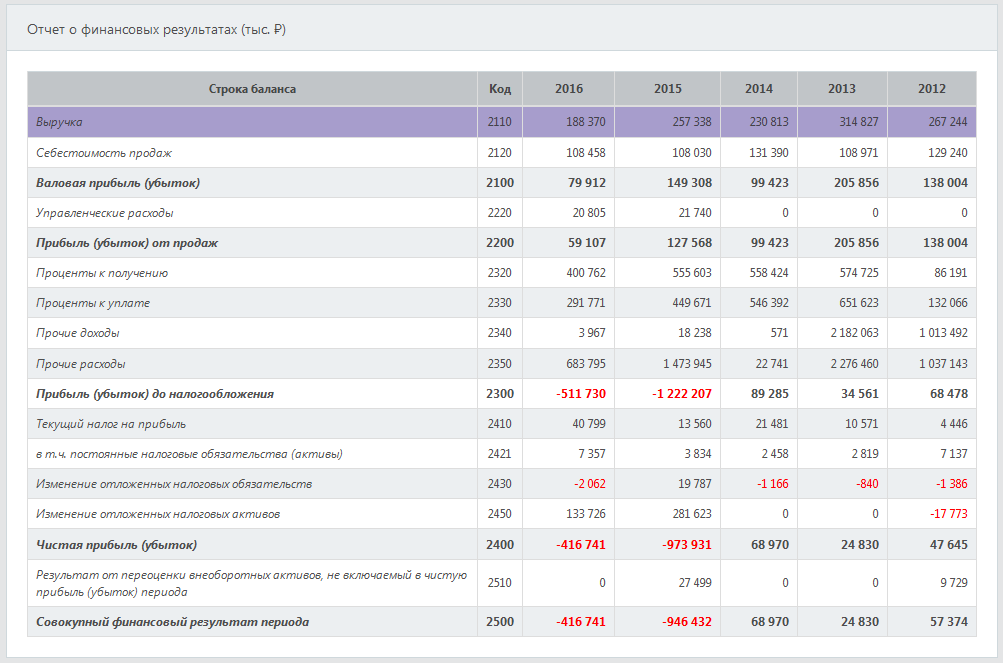
Для скоринга контрагента (заемщика) используются данные Формы 1 (балансовые данные компании)
и Формы 2 (отчет о финансовых результатах) официальной финансовой отчетности компании в Росстате.
Формы 1 и 2 содержат 58 показателей, однако многие из них встречаются в финансовой
отчетности
довольно редко.
Кроме того, некоторые показатели сильно коррелированны.
Подробнее с результатами статистических исследований данных Росстата можно ознакомиться
здесь.
После исключения редких и сильно коррелированных показателей было сформировано множество рабочих показателей,
которые используются при построении скоринговых моделей. Эти показатели приведены в таблице ниже.
| Код |
Строка баланса |
| 1100 | Итого по разделу I (ВНЕОБОРОТНЫЕ АКТИВЫ) |
| 1150 | Основные средства |
| 1200 | Итого по разделу II (ОБОРОТНЫЕ АКТИВЫ) |
| 1210 | Запасы |
| 1230 | Дебиторская задолженность |
| 1250 | Денежные средства и денежные эквиваленты |
| 1300 | Итого по разделу III (КАПИТАЛ И РЕЗЕРВЫ) |
| 1370 | Нераспределенная прибыль (непокрытый убыток) |
| 1400 | Итого по разделу IV (ДОЛГОСРОЧНЫЕ ОБЯЗАТЕЛЬСТВА) |
| 1410 | Заёмные средства |
| 1500 | Итого по разделу V (КРАТКОСРОЧНЫЕ ОБЯЗАТЕЛЬСТВА) |
| 1510 | Заёмные средства |
| 1520 | Кредиторская задолженность |
| 1600 | БАЛАНС (актив) |
| 2110 | Выручка |
| 2100 | Валовая прибыль (убыток) |
| 2400 | Чистая прибыль (убыток) |
Распределение значений показателей финансовой отчетности
близко к логнормальному,
в связи с чем осуществляется переход к логарифмическим шкалам.
Далее на основе отобранных показателей формируется множество производных показателей, включающее в себя все возможные
отношения. Часть из сформированных относительных величин имеет определенный экономический смысл и название (например,
коэффициент финансовой независимости, коэффициент общей оборачиваемости, чистая рентабельность и пр.), большая же часть
представляет собой формальные величины.
Наряду с данными официальной отчетности, для скоринга могут быть использованы также пользовательские данные
о контрагентах (например, сумма кредита, срок кредита и пр.). Эти данные загружаются пользователем на этапе создания
скоринговой модели в системе DaMIA-Скоринг.
3.2 Скоринговые модели DaMIA
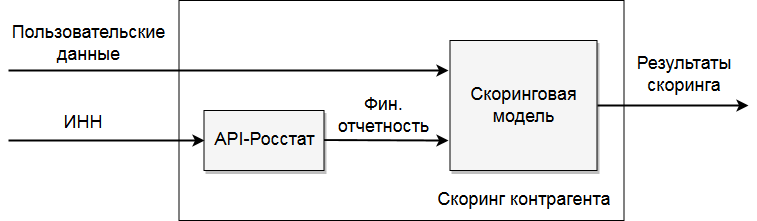
Скоринг контрагентов в системе DaMIA-Скоринг проводится в соответствии с некоторой скоринговой моделью.
На вход скоринговой модели подаются данные о контрагенте (данные официальной отчетности и/или пользовательские данные),
на выходе модель формирует результаты скоринга. Данные официальной отчетности получаются средствами
API-Росстат по ИНН контрагента. Схема использования скоринговой модели изображена на рисунке ниже.
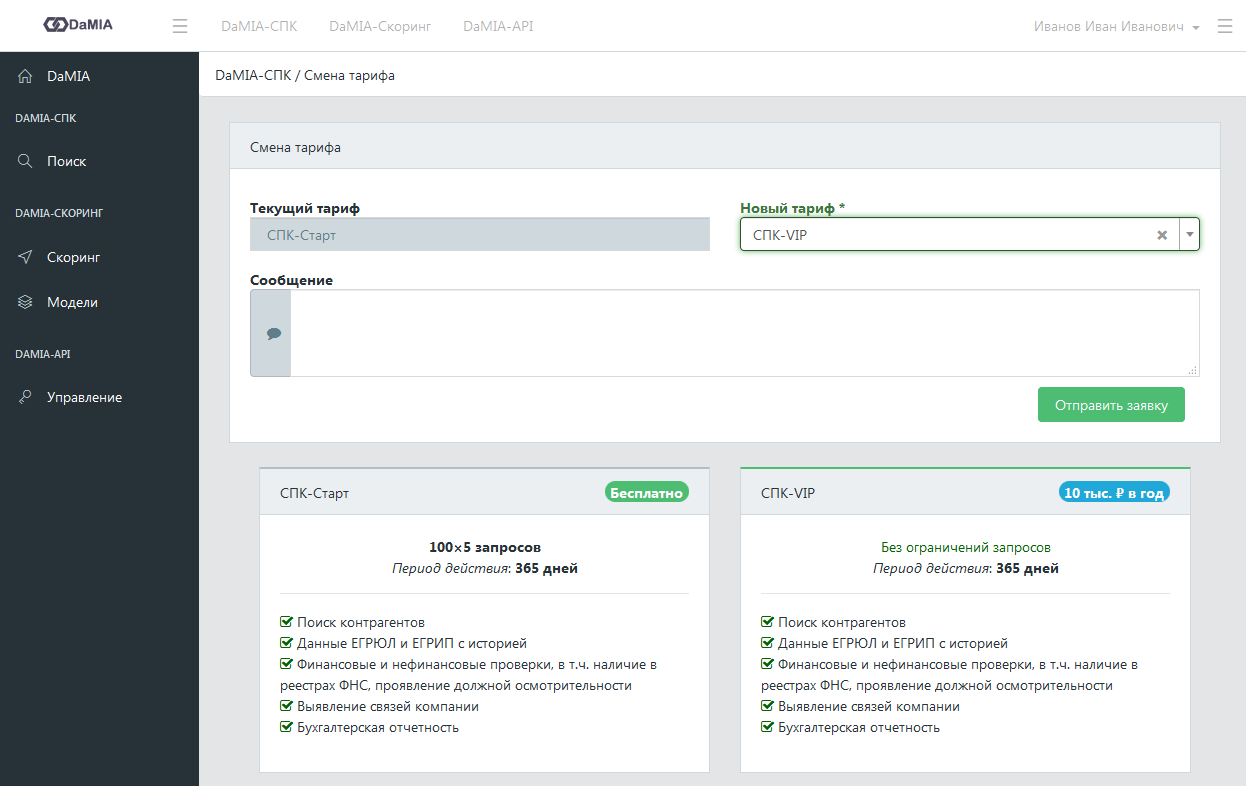
Скринговые модели создаются средствами системы DaMIA-Скоринг (вкладка Модели). Для создания скоринговой модели необходимо:
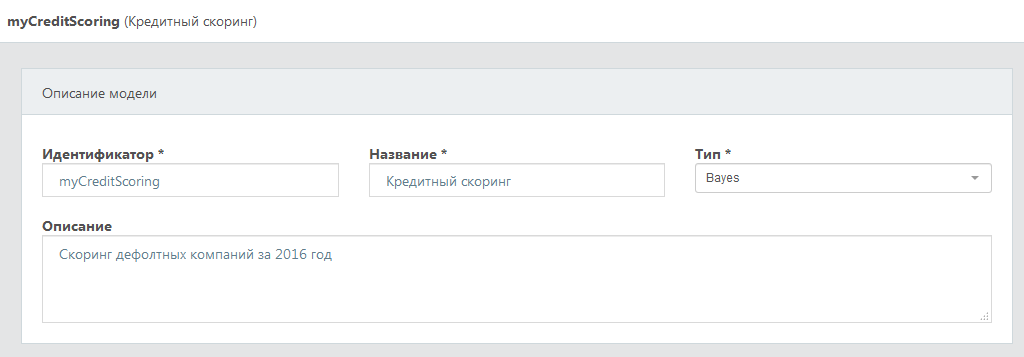
- Шаг 1. Сформировать описание модели
Необходимо указать идентификатор модели, название модели и выбрать тип модели.
Идентификатор модели – это уникальная строковая константа, которая используется при вызове модели через API-Скоринг.
Например, Вы указали идентификатор myCreditScoring для модели кредитного скоринга контрагентов, с которыми
работает Ваша организация. Тогда для получения результатов скоринга контрагента, например, с ИНН 6663003127,
в соответствии с этой моделью будет использоваться вызов:
https://damia.ru/api-scoring/score?model=myCreditScoring&inn=6663003127&key=<Ваш ключ>
Название модели – некоторое строковое описание модели (например, Кредитный скоринг).
Тип модели определяет алгоритм, в соответствии с которым будет построена скоринговая модель.
На текущий момент в системе DaMIA-Скоринг поддерживаются следующие типы скоринговых моделей:
- Байесовский классификатор (тип Bayes)
- Логистическая регрессия (тип Losgistic regression)
Подробное описание алгоритмов построения скоринговых моделей приведено
здесь.
Ниже представлен скриншот панели DaMIA-Скоринг с описанием скоринговой модели.
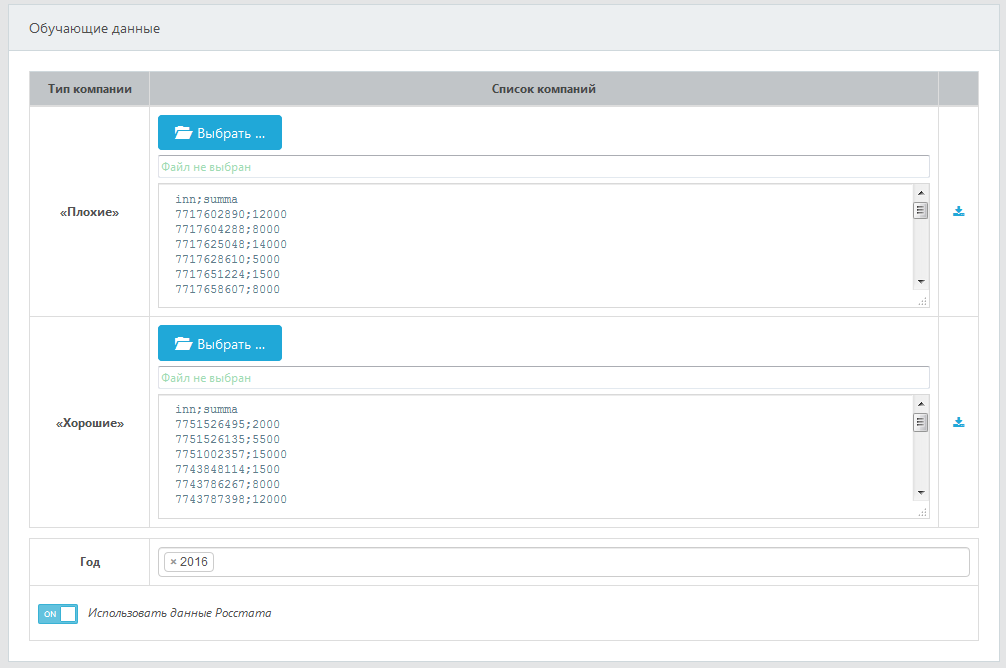
- Шаг 2. Загрузить обучающие данные
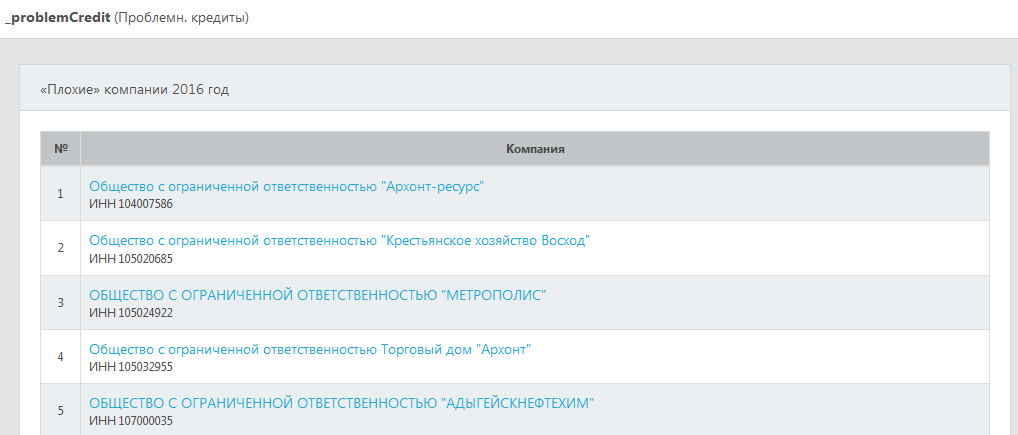
Обучающие данные для построения скоринговой модели представляют собой список ИНН контрагентов,
помеченных как "плохие" (например, ИНН компаний-банкротов при построении скоринговой модели банкротов;
ИНН компаний, допустивших дефолт по кредиту, при построении модели кредитного скоринга и т.д.),
и список ИНН контрагентов, помеченных как "хорошие" (например, ИНН контрагентов, успешно
выполнивших свои обязательства по кредиту).
Для каждого контрагента, помеченного как "плохой" или "хороший", наряду с ИНН, могут быть указаны дополнительные данные,
например, сумма кредита и срок кредита. Эти данные будут использоваться при обучении скоринговой модели.
В случае если список "хороших" контрагентов не указан, DaMIA-Скоринг будет считать "хорошими" всех остальных
контрагентов из базы Росстата, которые не являются "плохими".
При создании модели необходимо также указать год или годы, финансовая отчетность за которые должна быть
использована при обучении модели.
Скриншот панели загрузки обучающих данных изображен на рисунке ниже.
Списки "плохих" и "хороших" ИНН могут быть также загружены из csv-файла. Пример файла:
inn;summa
7717602890;12000
7717604288;8000
7717625048;14000
7717628610;5000
7717651224;1500
7717658607;8000
...
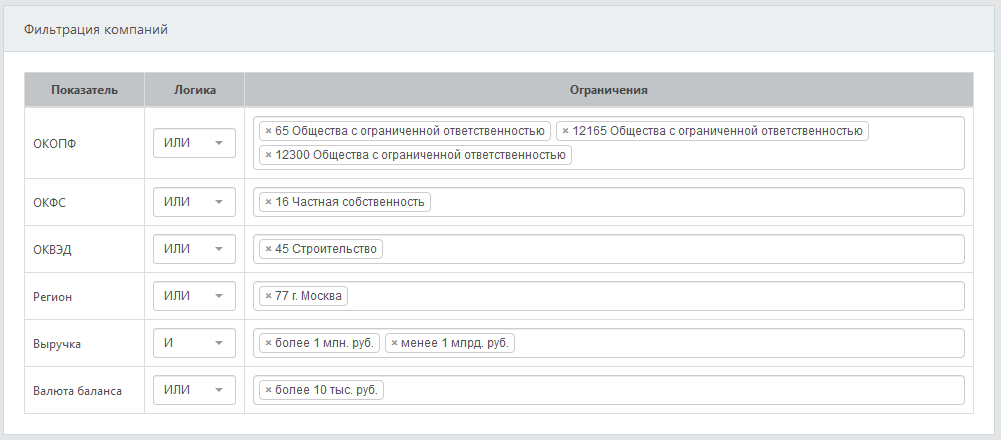
- Шаг 3. Выбрать фильтры
Для построения скоринговой модели будут использованы только те компании, которые удовлетворяют выбранным фильтрам.
Фильтрация компаний возможна по следующим критериям:
- ОКОПФ
Пример: 65, 12165, 12300 – Общества с ограниченной ответственностью
- ОКФС
Пример: 16 – Частная собственность
- ОКВЭД
Пример: 45 – Строительство
- Регион
Пример: 77 – г. Москва
- Выручка
Пример: выручка от 1 млн. руб. до 1 млрд. руб.
- Валюта баланса
Пример: валюта баланса более 10 тыс. руб.
На выходе скоринговой модели формируется степень принадлежности контрагента к классу "плохих" компаний (риск).
Диапазон значений
риска – от 0 до 1. Риски, близкие к нулю, означают низкую степень принадлежности к классу "плохих" компаний;
значения, близкие к 1, – высокую. Риски, близкие к 0.5, означают неопределенность в классификации контрагента –
его финансовая отчетность и/или пользовательские данные могут соответствовать случаю как "хороших", так и "плохих"
контрагентов.
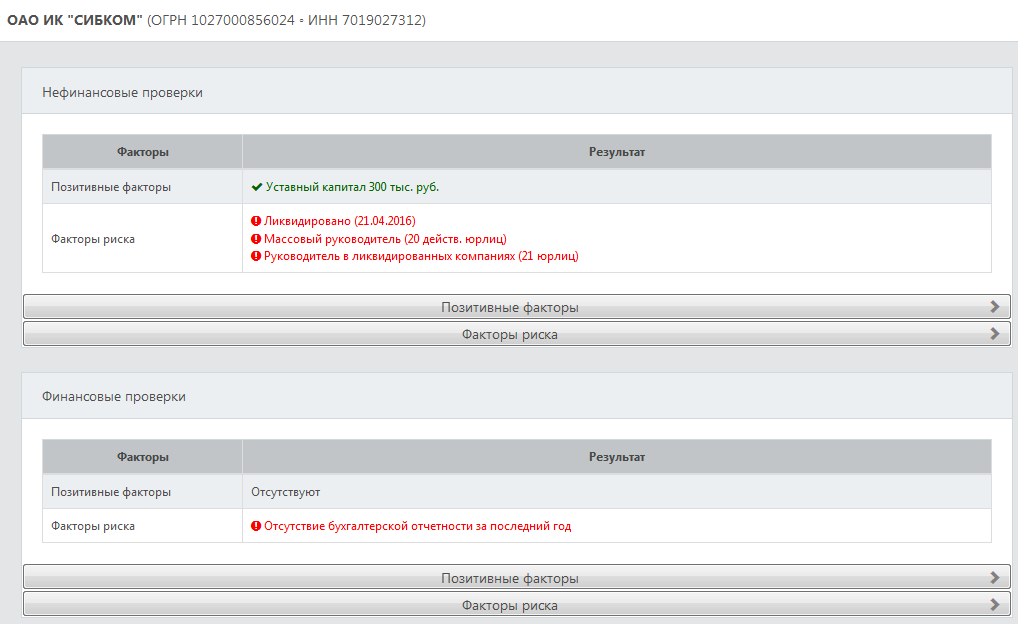
На текущий момент в системе DaMIA-Скоринг реализованы следующие скоринговые модели:
- Скоринг компаний-банкротов
- Скоринг компаний по "черному списку" 115-ФЗ
- Скоринг компаний дисквалифицированных лиц
- Скоринг компаний с проблемными кредитами
- Скоринг рискованной деятельности по данным Платформы «Знай своего клиента» ЦБ РФ
Подробное описание скоринговых моделей DaMIA приведено
здесь.
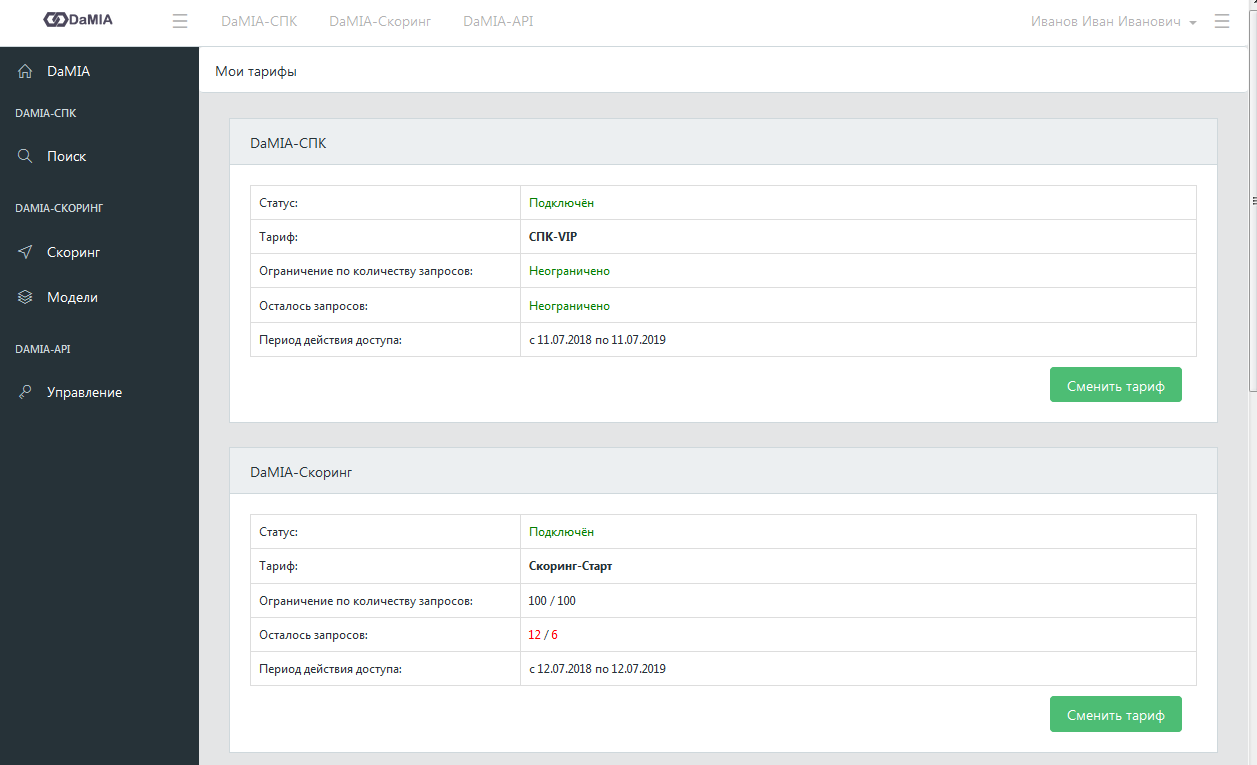
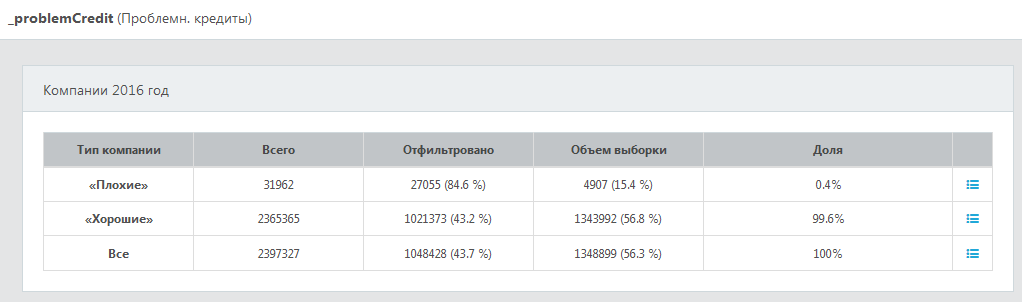
3.3 Обучающая выборка
Сводная информация о количестве "плохих" и "хороших" компаний отображается в системе DaMIA-Скоринг на вкладке "Обучение".
Скриншот панели изображен на рисунке ниже.
В столбце "Всего" приводится исходное количество компаний до фильтрации.
В столбце "Отфильтровано" указаны число и доля компаний, не удовлетворяющих выбранным фильтрам, для классов
"плохой" и "хороший", а также в совокупности по компаниям обоих классов.
Эти компании из дальнейшего рассмотрения исключаются.
В столбце "Объем выборки" указаны число и доля компаний, отобранных после фильтрации, для классов
"плохой" и "хороший", а также в совокупности по компаниям обоих классов.
В столбце "Доля" приводится доля каждого из классов в общем объеме выборки.
На вкладке "Обучение" можно посмотреть списки отобранных компаний, а также их карточки (если это позволяет Ваш тариф
в системе DaMIA-СПК).
Если при описании модели была указана опция "Использовать данные Росстата", то для построения скоринговой модели будут использованы
рабочие показатели финансовой отчетности, состав которых описан
выше. Эти показатели указываются
для значительного процента компаний в официальной отчетности, однако, после фильтрации компаний в соответствии выбранными
критериями может оказаться, что для компаний обучающей выборки некоторые из них будут редкими.
Рекомендуется такие показатели исключить, их использование в скоринге ненадёжно.
На вкладке "Обучение" приводится статистика по наличию балансовых данных для "плохих" и "хороших" компаний
обучающей выборки. Там же Вы можете указать, какие показатели исключить перед обучением скоринговой модели.
3.4 Обучение модели
Скоринговые модели DaMIA представляют собой
вероятностные модели
машинного обучения.
Для их построения используется только информация
о "плохих" и "хороших" компаниях, алгоритм обработки этой информации определяется в результате обучения.
На выходе модели формируется степень принадлежности компании к классу "плохих", принимающая значения в диапазоне от 0 до 1.
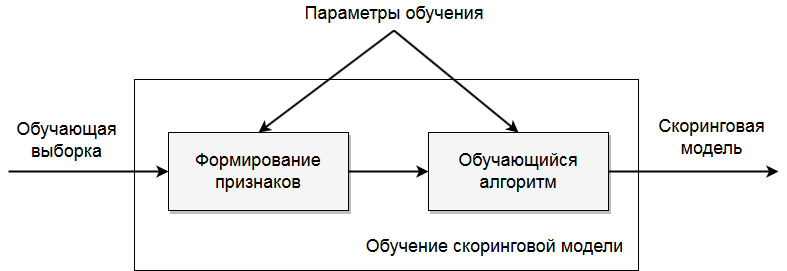
В процессе обучения происходит формирование и отбор признаков, настраиваются параметры модели. Схема обучения скоринговой
модели изображена на рисунке ниже.
На вход процедуры обучения подается обучающая выборка – совокупность данных официальной финансовой отчетности и/или
загруженные пользовательские данные для "плохих" и "хороших" компаний.
Из исходных признаков, содержащихся в обучающей выборке,
в соответствии с определенным алгоритмом происходит
формирование новых признаков.
Сформированные признаки поступают на вход
обучающего алгоритма.
В результате обучения формируется скоринговая модель.
В зависимости от качества исходных данных, в частности, степени разделимости "плохих" и "хороших" контрагентов,
а также от особенностей алгоритма обучения, обученная
скоринговая модель может иметь различную точность. Так, если данные финансовой отчетности и пользовательские данные
для "плохих" и "хороших" компаний сильно схожи, то их разделение с высокой точностью может оказаться невозможным.
В системе DaMIA-Скоринг используются следующие
показатели качества
обученной скоринговой модели.
- Вероятность ошибки 1-го рода, FPR (False Positive Rate)
Ошибка 1-го рода
возникает, когда к классу "плохих" была отнесена компания, имеющая метку "хорошая".
Вероятность ошибки 1-го рода оценивается как доля "хороших" компаний, отнесенных к классу "плохих", среди всех
"хороших" компаний.
- Вероятность ошибки 2-го рода, FNR (False Negative Rate)
Ошибка 2-го рода
возникает, когда к классу "хороших" была отнесена компания, имеющая метку "плохая".
Вероятность ошибки 2-го рода оценивается как доля "плохих" компаний, отнесенных к классу "хороших", среди всех
"плохих" компаний.
- Специфичность (Specificity)
Специфичность
показывает, какая доля "хороших" компаний была отнесена моделью к классу "хороших".
Модель с высокой специфичностью редко ошибочно относит к классу "плохих" компанию, которая на самом деле таковой не является.
Специфичность связана с вероятностью ошибки 1-го рода формулой:
Specificity = 1 – FPR
- Чувствительность (Sensitivity)
Чувствительность
показывает, какая доля "плохих" компаний была отнесена моделью к классу "плохих".
Модель с высокой чувствительностью редко ошибочно относит к классу "хороших" компанию, которая на самом деле таковой не является.
Чувствительность связана с вероятностью ошибки 2-го рода формулой:
Sensitivity = 1 – FNR
- Индекс Юдена (Youden's J statistic)
Индекс Юдена
рассчитывается на основе специфичности и чувствительности по следующей формуле:
J = Sensitivity + Specificity – 1
Чем выше специфичность и чувствительность, тем выше значения индекса Юдена. Минимальное значение, равное 0,
соответствует случайной классификации. Для безошибочной классификации индекс Юдена равен 1.
- AUC (Area Under ROC Curve)
Показатель AUC представляет собой площадь под
ROC-кривой результатов классификации (рисков)
и характеризует их разделимость.
AUC принимает значения из диапазона от 0 до 1. Значения AUC, близкие к 0.5, соответствуют максимальной неразделимости данных.
Если AUC близко к 1, то разделимость данных практически идеальная – для всех "хороших" компаний классификатор выдает значения риска,
близкие 0, для всех "плохих" – близкие к 1.
- Коэффициент Gini
Коэффициент Gini
имеет тот же смысл, что и показатель AUC, и связан с ним формулой:
Gini = 2AUC-1
В отличие от AUC, максимальной перемешанности данных будет соответствовать значение Gini, равное 0.
Для идеально разделимых данных коэффициент Gini так же равен 1.
3.5 Анализ обученной скоринговой модели
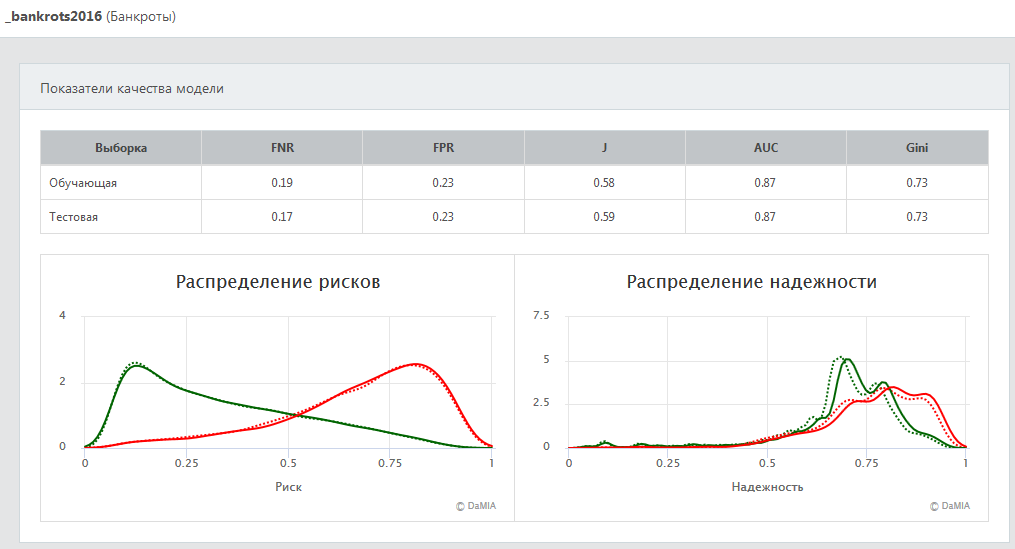
Показатели точности обученной скоринговой модели на обучающей и тестовой выборках
приводятся на вкладке "Анализ" системы DaMIA-Скоринг.
Данные обучающей выборки были использованы при формировании признаков и настройке параметров модели,
данные тестовой выборки скрыты на этапе обучения модели, они прогоняются через модель после завершения её обучения.
По результатам прогона обучающих и тестовых данных через модель строятся распределения полученных рисков и их надёжностей.
Графики этих распределений изображены на панели "Показатели качества модели" (пунктирная линия – для обучающей выборки,
сплошная – для тестовой). У качественных моделей плотность распределения рисков для "плохих" компаний должна быть
много больше, чем для "хороших" компаний при значениях риска, больших 0.5, и много меньше при значениях риска, меньших 0.5.
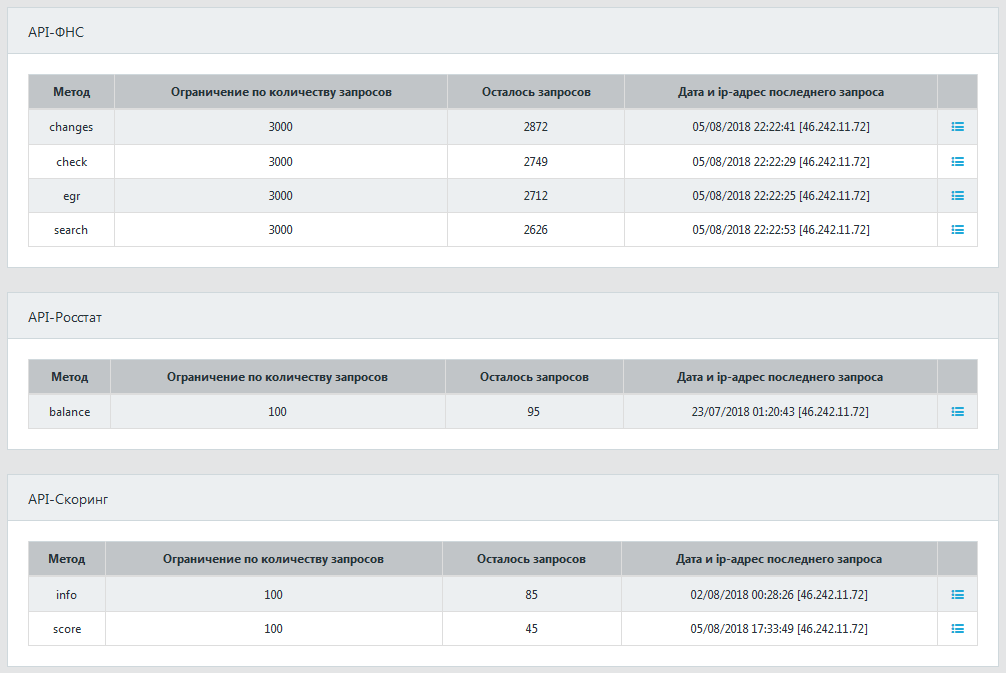
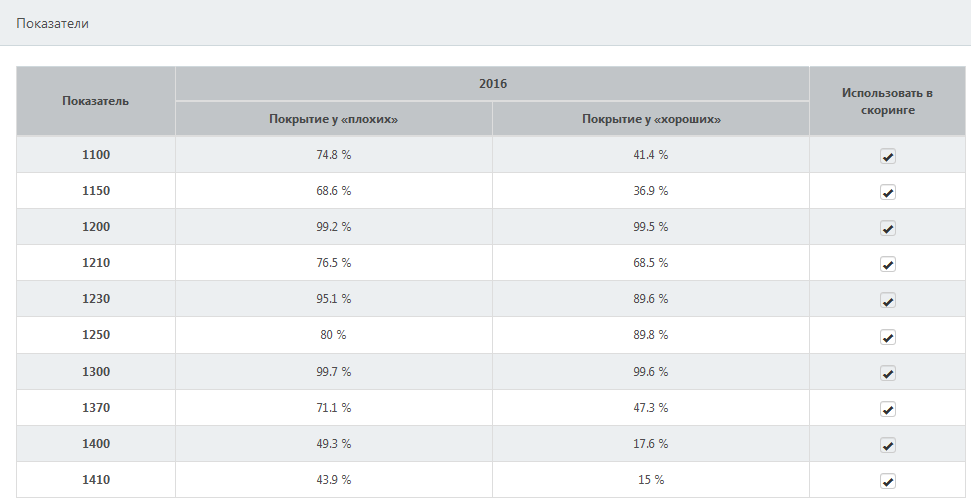
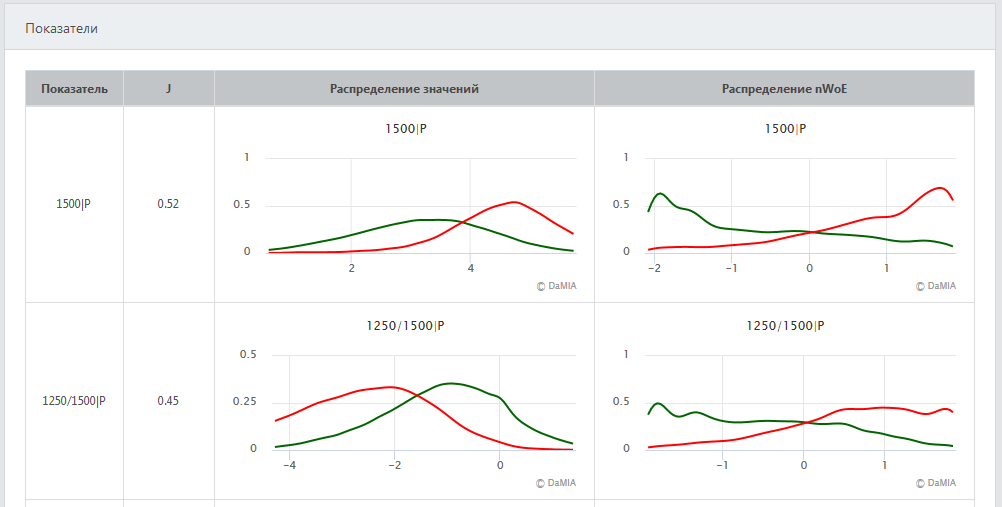
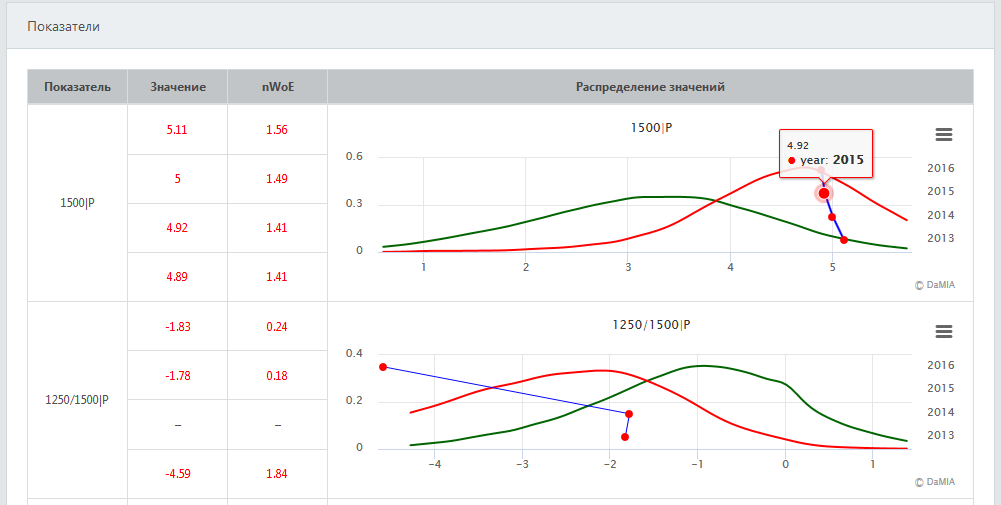
Информация об используемых в модели показателях приводится в таблице на панели "Показатели".
Таблица содержит следующие столбцы.
- Показатель
Название показателя (содержит код строки финансовой отчетности или название полозовательского показателя).
После знака прямого слэша "|" указывается дополнительная информация о показателе (флаги): P – используются только
положительные значения; N – используются только отрицательные значения.
Например, показатель 1250/1500|P представляет собой отношение строк 1250 (Денежные средства и денежные эквиваленты)
и 1500 (Краткосрочные обязательства) финансовой отчетности, при этом флаг "P" означает, что этот показатель
рассчитывается только в том случае, если оба значения 1250 и 1500 положительные.
- J
Индекс Юдена, соответствующий показателю, – это индекс Юдена классификатора, который использовал бы только
значения этого показателя. Высокие значения индекса Юдена у показателя говорят о его важности для скоринга.
Показатели с низкими значениями индекса Юдена в
наивном байесовском классификаторе
(тип скоринговой модели –
Bayes),
практически бесполезны.
Однако, в классификаторах, не предполагающих рассмотрение каждого признака не зависимо от остальных
(например, в
логистической регрессии,
тип скоринговой модели –
Logistic regression),
низкие значения индекса Юдена у признака еще не означают его бесполезность -
признак может играть важную роль в совокупности с другими признаками.
- Распределение значений
Для каждого признака оцениваются его распределения у "плохих" и "хороших" компаний.
По графикам можно определить, есть ли различия в значениях признака у компаний разных классов.
Если распределения значений признака для "плохих" и "хороших" компаний существенно различаются, то такой признак,
как правило, играет важную роль в скоринге.
Если же распределения практически одинаковые, то данный признак бесполезен для скоринга по его отдельным значениям.
- Распределение nWoE
Каждое значение признака характеризуется показателем
WoE
(Weight of Evidence).
По определению, WoE – это логарифм
отношения вероятностей
(odds ratio) того, что признак примет данное
значение для "хороших" компаний и для "плохих" компаний.
Чем больше WoE отличается от нуля для данного значения признака, тем более это значение
характерно для того или иного класса. Значения WoE, близкие к нулю, говорят о равновероятной
возможности этого значения как для "хороших", так и для "плохих" компаний.
Положительные WoE имеют те значения признака, которые чаще встречаются у "хороших" компаний,
отрицательные – у "плохих".
На графиках в данном столбце представлены распределения значений nWoE (negative WoE) для "хороших" и "плохих" компаний.
В идеальном случае, все "плохие" компании должны иметь только положительные nWoE, все "хорошие" – только отрицательные.
На практике, некоторые "плохие" компании будут иметь отрицательные nWoE, а некоторые "хорошие" – положительные nWoE.
Это происходит из-за того, что значения рассматриваемого показателя для таких компаний попадают в область,
статистически более вероятную для другого класса.
3.6 Результаты скоринга
После того, как модель обучена, её можно использовать для скоринга Ваших контрагентов или заемщиков. Если Вы подключены
к
API-Скоринг,
то получение результатов скоринга будет доступно также через API.
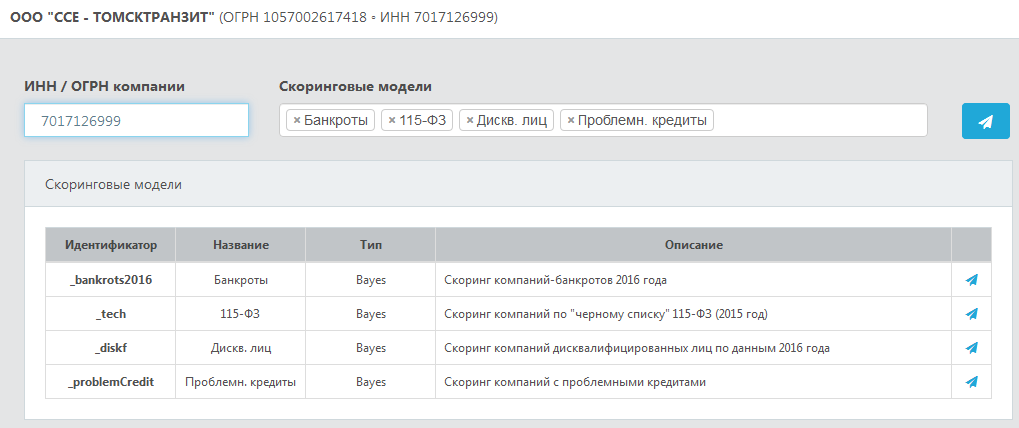
Для скоринга контрагента необходимо указать ИНН или ОГРН контрагента и выбрать скоринговую
модель из списка доступных (это встроенные модели DaMIA и Ваши обученные модели).
На выходе скоринговой модели формируются следующие результаты:
- Риск контрагента
Риск контрагента – это степень принадлежности контрагента к классу "плохих". Диапазон значений риска – от 0 до 1.
Как правило, значения риска, близкие к 0, получаются случае, когда данные контрагента (из официальной отчтетности Росстата и/или
загруженные пользовательские данные) в некотором смысле близки к данным "хороших" компаний и далеки от данных "плохих" компаний.
Значения риска, близкие к 1, наоборот, будут, если данные контрагента далеки от данных "хороших" компаний
и близки к данным "плохих" компаний.
Значения риска около 0.5 означают, что данные контрагента одинаково близки как к "плохим", так и "хорошим"
компаниям.
Чем выше риск, тем в большей степени модель относит котрагента к классу "плохих".
- Зона риска
Зона риска определяется на основе рассчитанного значения риска. Возможные зоны риска:
- Зеленая зона (Низкий риск).
- Желтая зона (Средний риск).
- Красная зона (Высокий риск).
Границы зон определяются в результате статистического анализа рисков, формируемых моделью для компаний Росстата.
Каждая скоринговая модель в общем случае имеет свои границы зон риска.
- Скоринговый балл
Скоринговый балл – величина, связанная с риском контрагента, и принимающая значения от 0 до 5.
Скоринговый балл, близкий к 0, соответствует высокому риску; близкий а 5 – низкому.
- Зона скорингового балла
Зона скорингового балла определяется на основе рассчитанного значения скорингового балла.
Возможные зоны скорингового балла:
- Зеленая зона (Низкий балл).
- Желтая зона (Средний балл).
- Красная зона (Высокий балл).
Границы зон определяются в результате статистического анализа скоринговых баллов, формируемых моделью для компаний Росстата.
Каждая скоринговая модель в общем случае имеет свои границы зон скорингового балла.
- Надежность
Риск заемщика (контрагента) рассчитывается по данным бухгалтерской отчетности Росстата и/или загруженных пользовательских данных
(например, сумм кредита и т.д.). Однако, для заемщика некоторые строки баланса могут отсутствовать в официальной отчетности.
Также могут отсутствовать и некоторые пользовательские данные.
Если данных о заемщике мало, то рассчитанное значение риска будет ненадёжным.
Надёжность связана с количеством известных и использованных для расчёта риска данных о заемщике.
Надежность принимает значения из диапазона от 0 до 1. Значения, близкие к 0, означают низкую надежность; близкие к 1 – высокую.
- Зона надежности
Зона надежности определяется на основе рассчитанного значения надежности. Возможные зоны надежности:
- Зеленая зона (Низкая надежность).
- Желтая зона (Средняя надежность).
- Красная зона (Высокая надежность).
Границы зон определяются в результате статистического анализа надежностей, формируемых моделью для компаний Росстата.
Каждая скоринговая модель в общем случае имеет свои границы зон надежности.
Для получения результатов скоринга в системе DaMIA-Скоринг необходимо указать ИНН/ОГРН контрагента и выбрать скоринговые модели.
Ниже приведен скриншот панели скоринга.
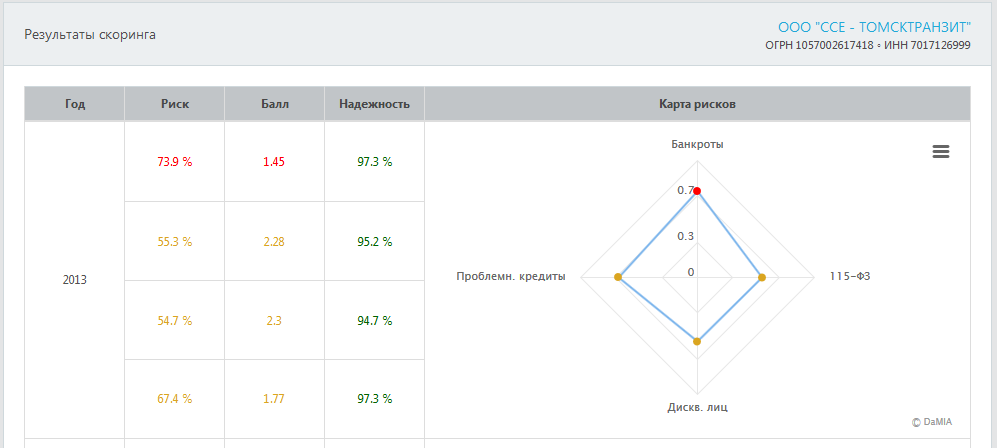
Результаты скоринга для каждого года представляются в виде скоринговой карты, по осям которой отложены значения рисков,
рассчитанные с помощью выбранных скоринговых моделей. Цвета отложенных точек соответствуют зонам риска (зеленая,
желтая, красная зоны). Пример скоринговой карты в пространстве рисков банкротства, соответствия "черному списку" компаний
по 115-ФЗ, компаний с дисквалифицированными учредителями и компаний с проблемными кредитами изображен на рисунке ниже.
Рассчитанные значения рисков, скоринговых баллов и надежностей для каждой скоринговой модели и каждого года также
приведены в столбцах таблицы.
Для более подробного просмотра результатов скоринга по отдельным скоринговым моделям нужно нажать на соответствующую
кнопку в таблице "Скоринговые модели".
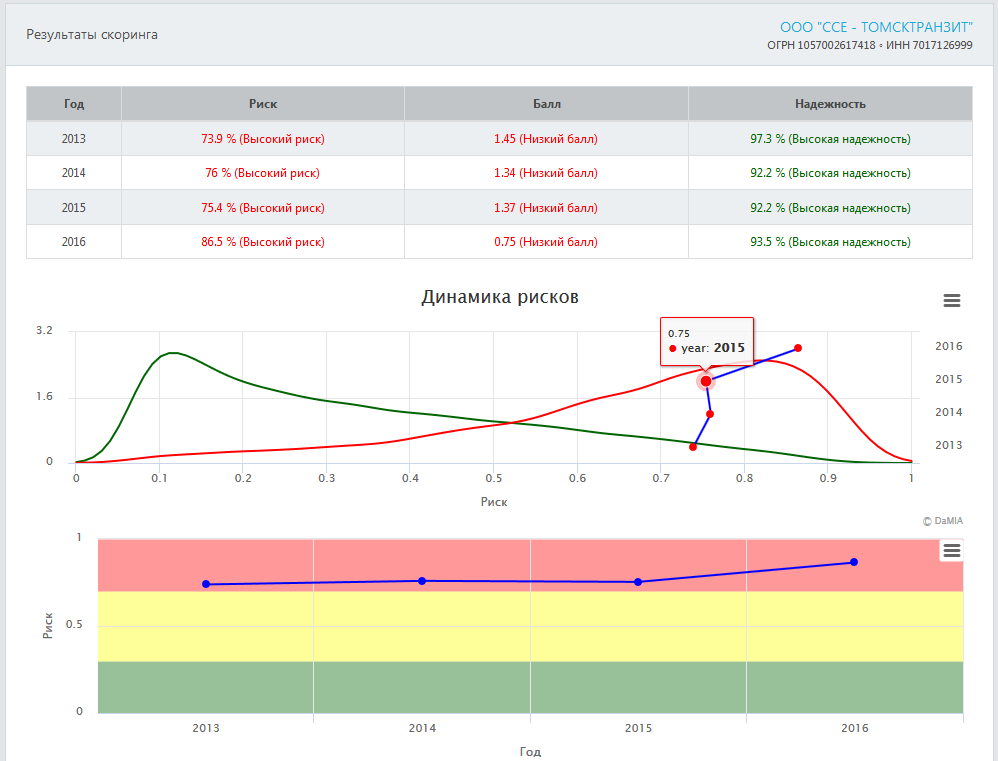
В результатах скоринга можно проследить динамику изменения рисков по годам. Значения рисков для каждого года совмещены
с графиками плотностей распределений рисков для "плохих" и "хороших" компаний, что позволяет понять, насколько
данное значение риска было характерно для "плохих" и "хороших" компаний в разные годы.
На график динамики риска также нанесены зоны риска (красная, желтая и зеленая). Примеры графиков представлены на рисунке ниже.
На панели "Показатели" приведены графики динамики показателей, использованных в скоринге, по годам.
Значения показателей также наложены на графики плотностей распределения для "плохих" и "хороших" компаний.
В столбце "Значение" приведены значения показателей, в столбце "nWoE" – соответствующие им значения nWoE.
Чем больше значение nWoE, тем в большей степени данный показатель увеличивает итоговый риск контрагента.
Если же значение nWoE отрицательное, то данный показатель приводит к уменьшению риска контрагента.
Примеры графиков распределений показателей с наложенными на них значенями показателей приведены ниже.